Redis、( 二 )

Redis、( 二 )
TONG HUIRedis 缓存雪崩、缓存击穿、缓存穿透
缓存雪崩
指缓存中数据大批量到过期时间,请求都直接访问数据库,引起数据库压力过大甚至宕机。
缓存击穿
指热点key在某个时间点过期,而在这个时间点对这个Key有大量的并发请求,从而请求到数据库。
缓存穿透
指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
Redis 过期策略和内存淘汰策略
过期策略
定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即对key进行清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
设置 set key 60,指定这key60s后过期。
惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
- lazyfree-lazy-eviction:当 redis 内存达到阈值 maxmemory 时,将执行内存淘汰
- lazyfree-lazy-expire:当设置了过期 key 的过期时间到了,将删除 key
- lazyfree-lazy-server-del:这种主要用户提交 del 删除指令
- replica-lazy-flush:主要用于复制过程中,全量同步的场景,从节点需要删除整个 db
- lazyfree-lazy-user-del :当设置为 yes 时,本质来说和 unlink 指令的处理方式一致了。
定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。
- hz : 执行定期任务的频率,默认为 10
内存淘汰策略
当设置了 maxmemory 这个配置时,可以 在maxmemory-policy: 指定以下淘汰策略。
- volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
- allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
- volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
- allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
- volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
- allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
Redis 持久化
RDB
在指定的时间间隔内,将内存中的数据写入磁盘,恢复时,将快照文件读入内存中
- save : save 900 1、save 300 10、save 60 10000 ,分别表示 900 秒(15 分钟)内有 1 个更改,300 秒(5 分钟)内有 10 个更改以及 60 秒内有 10000 个更改。
- 优点
适合大规模的数据恢复场景,如备份,全量复制等 - 缺点
没办法做到实时持久化/秒级持久化。
新老版本存在RDB格式兼容问题
手动触发分
save命令:阻塞当前Redis服务器,直到RDB过程完成为止,redis服务器在快照创建完毕之前将不在响应任何其他的命令,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用
bgsave命令:客户端可以使用BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork来创建一个子进程,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件,而父进程则继续处理命令请求,Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短
自动触发
- redis.conf中配置 save m n ,即在m秒内有n次修改时,自动触发bgsave生成rdb文件;
- 主从复制时,从节点要从主节点进行全量复制时也会触发 bgsave 操作,生成当时的快照发送到从节点;
- 执行 debug reload命令重新加载redis时也会触发bgsave操作;
- 默认情况下执行 shutdown命令时,如果没有开启aof持久化,那么也会触发 bgsave操作;
AOF
采用日志的形式来记录每个写操作,追加到文件中,重启时再重新执行AOF文件中的命令来恢复数据。它主要解决数据持久化的实时性问题。默认是不开启的。同时启用RDB和AOF,进行恢复时,默认AOF文件优先级高于RDB文件,即会使用AOF进行恢复。
- 优点
数据的一致性和完整性更高 - 缺点
AOF记录的内容越多,文件越大,数据恢复变慢。
- appendonly no/yes 是否开启aof
- appendfilename “appendonly.aof”
- appendfsync no / always #每次 / everysec #每秒一次
Redis 高可用
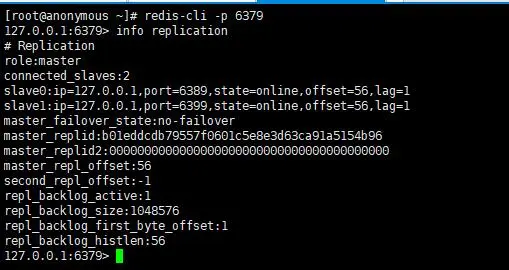
主从模式
- 在安装目标中复制一份redis.conf配置文件
- 启动Redis节点 redis-server /data/redis-stable/redis.conf
- 启动Redis节点 redis-server /data/redis-stable/redis2.conf
- 启动Redis节点 redis-server /data/redis-stable/redis3.conf
- 主节点 redis1.conf
- daemonize yes
- bind 0.0.0.0

- 从节点 redis2.conf,redis3.conf
- daemonize yes
- bind 0.0.0.0
- port 6389,6399
- replicaof
// ip空格port 指定主节点地址端口 - masterauth
// 主节点密码,没有不用开启
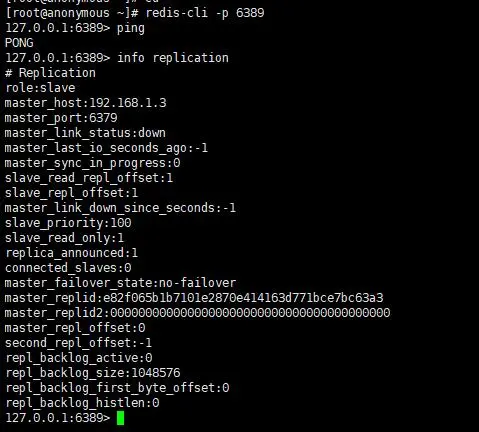
哨兵模式
- 在安装目标中复制一份sentinel.conf文件
- 启动哨兵节点1 redis-sentinel /data/redis-stable/sentinel.conf
- 启动哨兵节点1 redis-sentinel /data/redis-stable/sentinel2.conf
- 启动哨兵节点1 redis-sentinel /data/redis-stable/sentinel3.conf
- 修改配置 sentinel.conf,sentinel2.conf,sentinel3.conf
- port 26379,26380,26381
- daemonize yes
- sentinel monitor mymaster 127.0.0.1 6379 2
- 启动redis服务和哨兵服务
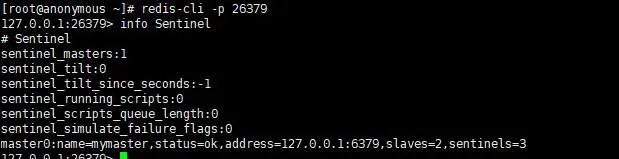
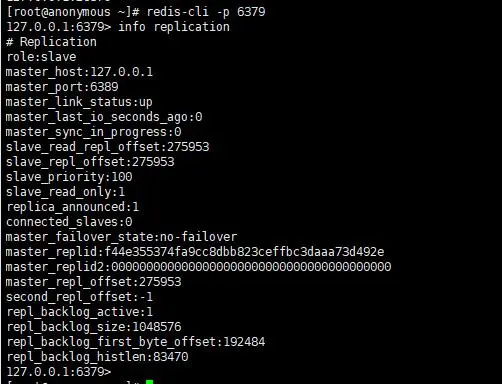
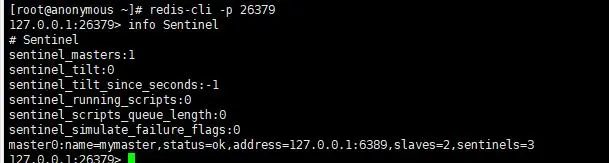
- 查看哨兵节点
address:主节点信息
slaves:从节点数量
sentinels:哨兵数量 - 验证哨兵是否可用
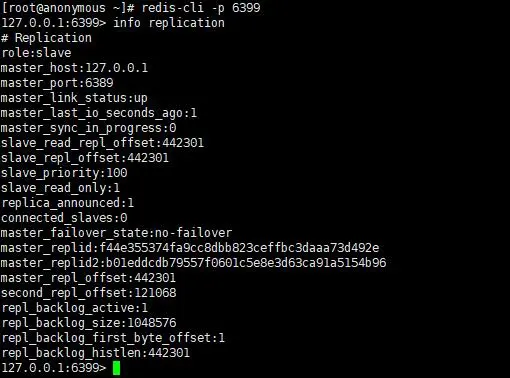
- 开始
- 关闭主节点后
- 开始

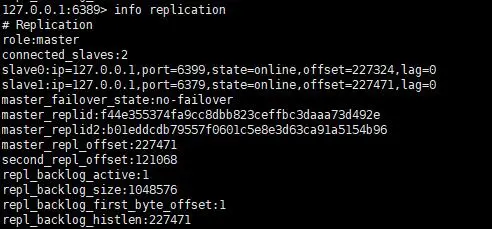
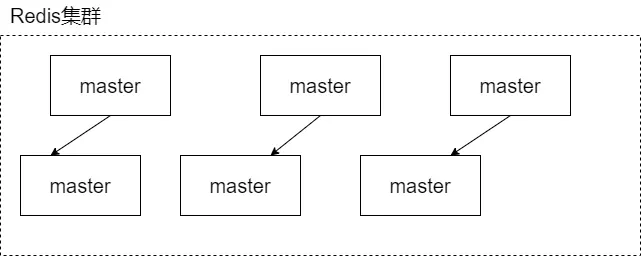
集群模式
- 在安装目标中复制一份redis.conf配置文件
- 启动Redis节点 redis-server /data/redis-stable/redis.conf
- 启动Redis节点 redis-server /data/redis-stable/redis2.conf
- 启动Redis节点 redis-server /data/redis-stable/redis3.conf
- 修改配置
- cluster-enabled yes
- cluster-config-file nodes-6399.conf
- cluster-node-timeout 15000
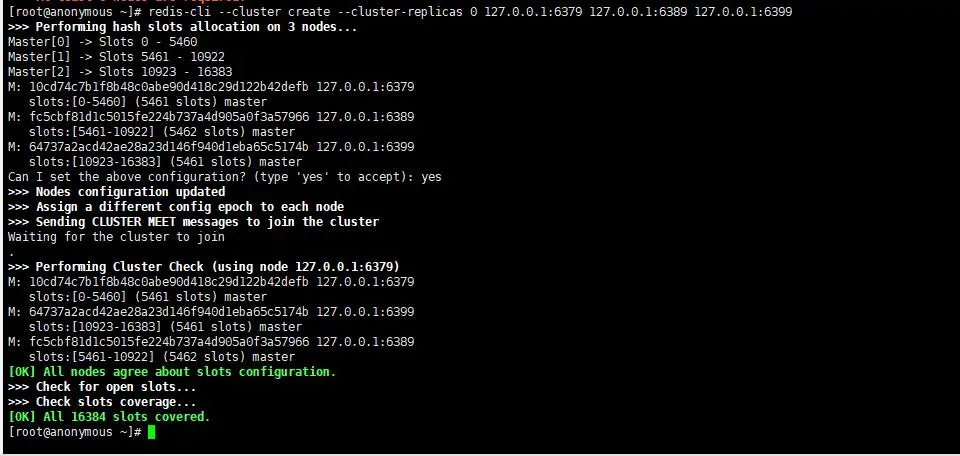
- 创建集群
- 执行 redis-cli –cluster create –cluster-replicas 0 127.0.0.1:6379 127.0.0.1:6389 127.0.0.1:6399
- 0 : 对应从节点的数量,上图所示:master 下的从节点数量。
- ip:端口 : 为所有节点(主从)
- 输入yes
- 集群验证
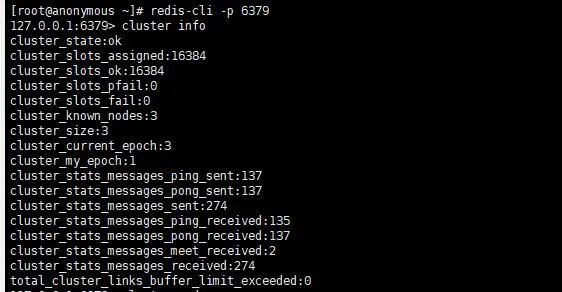
- 集群信息
- 节点信息
- 集群信息
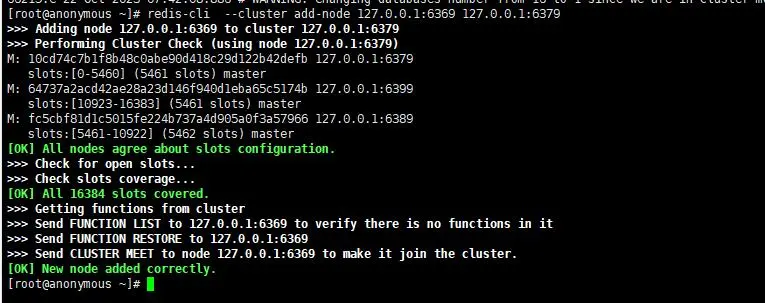
- 添加节点
- 执行 redis-cli –cluster add-node 127.0.0.1:6369 127.0.0.1:6379
- 输入yes
- 节点信息